SOFTWARE ENGINEERING
BY KARL E. WIEGERS
Over the past several months, we've talked a lot about concepts that distinguish the discipline of software engineering from the art of computer programming. The underlying theme has been that a disciplined, structured approach to software development will result in a final product of higher quality and greater durability than will a more casual approach. This durability becomes particularly important when your software system enters the maintenance phase, which is everything that you do to the system after you thought you were done with it. Another of our goals is to design and write program modules so that they can be reused in future projects, thereby saving us the pain of continually reinventing all sorts of wheels.
We've talked a lot about how to decompose even a very complex software system into a collection of well-defined, bite-sized processes. If we do this properly, we can go off and write program modules (subroutines, functions, procedures) in our favorite language with confidence that we'll be able to plug the pieces together successfully at the end. Last time, we looked at some ideas for documenting our final product, in the form of both internal comments describing each specific program module and external documentation showing how the system as a whole fits together and operates.
The one aspect of software development we really haven't addressed is the actual writing of the computer program itself. I've been making the assumption that most of you are seasoned programmers, with some experience in modern structured languages such as C, Pascal or GFA BASIC. But perhaps the time is ripe to re-hash a topic that helped begin the software engineering revolution: structured programming. Some other thoughts that aren't specifically part of structured programming might be described better as smart programming. I touched on some of these basic ideas back in the November 1988 issue; now let's take a closer look.

STRUCTURED • PROGRAMMING
While programming, continually ask yourself,
"How would I like to be the one who has to read, understand and change this program in the future?"
What is structured programming?
It's difficult to provide a concise answer to this question. In some ways, it fits into the "I know it when I see it" category, although we will discuss some specific structured programming principles shortly. But on the other hand, structured programming is consistent with our general philosophy of software engineering, which emphasizes enhanced communication between people. Computer hardware has become powerful enough that programmers should no longer emphasize compactness of code and cleverness of algorithm on their road to the nirvana of "efficiency." Contemporary software development stresses clarity and structure of code, not cuteness.
While programming, continually ask yourself, "How would I like to be the one who has to read, understand and change this program in the future?" Structured programming can be a powerful aid to effective software maintenance. And in some ways, structured programming is an attitude, as well as a behavior. The emphasis is on person-to-person efficiency, not computer efficiency.
The golden rule
In my opinion, the single most important idea of structured programming is that the code you write should represent a clear, simple and straightforward solution to the problem at hand. Keep this guiding principle in mind as you read the rest of this article.
Start at the top
One of the basic precepts of structured programming has been with us clear through our software engineering sojourn: a structured program consists of a hierarchical collection of individual modules, which appear more abstract at the top levels and more detailed at the lower levels. This fits with our overall strategy of hierarchical decomposition, which we've followed from structured system specification through structured design and now down to structured programming. The process of building a program in this fashion is called "top-down programming," or step-wise refinement.
Another point I stressed during our discussion of program design is that each of these modules (or processes, in design terms) communicates with others through well-defined data interfaces. These data interfaces typically are subroutine parameter lists or function argument lists. Each part of the program appears to other parts as a black box that simply performs its assigned function in some unknown way.
You've encountered this idea every time you called a built-in function in some programming language. Think about 8-bit Atari BASIC. Do you recall the STICK function? It told you something about the position of the joystick. Do you know how to communicate with the STICK function? Yes; all you had to do was pass it the number of the joystick you were interested in, like this: STICK(1), and it returned a numeric answer. Do you know how it worked? No; could be magic, for all you know. Do you care? No. This is the beauty of a "black box" approach to software development. There's no reason why the modules you write should be any different in this regard than the modules supplied by the guys who wrote the language you're using.
In practice, you apply the notion of step-wise refinement by writing your initial description of each fundamental process in a very high-level "language" that we called pseudocode. This is a first attempt at a picture of how each process will accomplish its assigned task. As you continue down the path from design toward code, you add detail to this description until eventually you reach something that conforms to the exact syntax of the language you're using: source code.
I suppose we could consider that one additional step takes place even after this, which is the compiling of your source code into something the computer can deal with: object code. Fortunately, we humans can halt our step-wise refinement at the source code stage and let the machine take over from there. (Someday, we'll be able to stop at the pseudocode stage.)
The dreaded GOTO
The first thing most people learn about structured programming is that you shouldn't use GOTO statements. This notion stems from an article published in 1968 by E. W. Dijkstra, which helped the structured programming push get underway in earnest. The succinct title said it all: "Go To Statement Considered Harmful" (Communications of the ACM, 11 (3), 147-148).
We don't always have a choice. In older forms of BASIC, GOTO statements were needed everywhere, because there just wasn't the richness of commands that we need to avoid GOTO. The careless use of GOTO inevitably leads to the notorious "spaghetti code" that makes a program nearly impossible to comprehend and debug. The worst case is a GOTO that branches back to a previous statement in the program listing.
Modern programming languages provide logic and control commands that allow us to almost completely avoid using GOTO statements (we'll discuss these shortly). However, there are still a few situations in which a GOTO actually can result in cleaner, more understandable code. Error-handling situations sometimes benefit from GOTOs. Premature exits from loops, or breaking out of deeply nested IF structures, may be more easily handled with a GOTO than by some other method. Nonetheless, the general guideline that GOTOs should not be used for routine transfer of control within a program is still valid, so try to break any lingering bad habits from your earlier experiences with BASIC interpreters.
A question of style
The programming style you use can greatly influence the readability of your code. While not strictly part of structured programming, there are some matters of style to keep in mind. A pretty good book on this topic is The Elements of Programming Style, Second Edition, by Kernighan and Plauger (McGraw-Hill, 1978). It's somewhat dated, and the code examples are all in FORTRAN or PL/I, but the principles remain the same. The following represent some of the highlights of programming style in my mind; some don't apply to all programming languages.
Use indentation to visually block logically related sections of your code, such as the sections of IF/ELSE IF/ELSE/END IF and SELECT/CASE constructs. Use blank lines in the source code to further delineate sections of the program. Use comments judiciously in the source code for clarification (we talked about this last time), and make sure the comments are accurate. Don't bother to document bad code—rewrite it, instead. Never put more than one statement on the same source line. We always did this in Atari BASIC because it saved six bytes per statement, but you don't need such tricks when you have a megabyte at your disposal.
Select meaningful variable and procedure names. Don't use different names to represent the same piece of information (refer to your data dictionary). Explicitly declare the type of each variable used, if your language permits this. Use parentheses to resolve any ambiguities in mathematical expressions, even if they aren't required for the operation to be executed correctly. Make sure conditional tests (IF some condition THEN do something) read clearly. Generally speaking, the first condition tested for should be the desired condition, with an error condition handled second.
Program defensively: Try to anticipate all possible errors in input data or mathematical operations, and write code to handle such situations. This includes validating input data before trying to use it and testing for such mathematical problems as division by 0 or taking the logarithm of a negative number. Make sure that input data does not exceed the bounds of what the routine can handle. Think of the user when designing your programs; make input easy to prepare correctly, and make output self-explanatory.
Initialize variables before using them. Who knows what was in those bytes before they were reserved for a variable's use? Avoid multiple entry points, and exits from loops and subroutines (more about this later).
The first priority is to get the program running correctly. You can worry about optimization later. And when you do, make sure the program still runs correctly. Don't try to optimize every little step; the compiler will do a lot of this for you. Usually, a program spends most of its time in a small section of the code, so concentrate your optimization efforts here (if you can find it).
Use the best algorithms you can find for calculations, but remember that both the algorithm and the structure of your data will influence how the algorithm will be implemented in code. Insert "instrumentation" checkpoints in your programs to write out intermediate results someplace; so that you can verify accuracy, track down errors and assess efficiency. These outputs can be sent to a trace file on the disk, which you can then examine at your leisure.
Building blocks
Another basic premise of structured programming states that any program logic, no matter how complex, can be expressed in terms of just three kinds of logical operations: sequence, selection and iteration. A program then is made up of a series of blocks of code to perform these operations. Let's define these three kinds of operations.
Sequence—a series of program statements are executed one after the other, in the order in which they appear in the source code. Obviously, this rules out statements like GOTO and IF, restricting us just to statements that perform some specific action. (A CALL or GOSUB to another procedure would qualify as an action in this sense.) Hence, a block of statements that are executed sequentially is called an "action block."
Selection—one set of statements, from a choice of two or more, is selected for sequential execution, based on some criterion. One way to accomplish this is to use an IF/THEN/ELSE construct. Some of the languages will also permit a SELECT/CASE/OTHERWISE/END - type structure, perhaps with different but analogous keywords. The set of statements that gets executed in each case is itself an action block. Sometimes selection constructs are called "branch blocks."
Iteration—a series of statements is executed repeatedly until some termination condition is met. These are also called "loop blocks." Virtually all languages contain simple FOR/NEXT or DO/END-type loops. More modern languages include variations such as DO UNTIL/END and DO WHILE/END.
These three kinds of "control blocks" have some features in common. First, the code in each is executed from top to bottom, which is the same way that it appears in the source file. This makes the program much easier to read and understand than does the convoluted branching you find in so many BASIC programs. Of course, in a selection block, not every statement is executed, and in a loop block they may be executed more than once, but they still are always executed from top to bottom.
In addition, each control block has just one logical entry point: the first statement. And if they're well structured, they have just one logical exit point: the last statement. A complete program is written by assembling and nesting blocks of these three kinds to perform the required processing.
Believe it or not, it's possible to write more or less structured programs in BASIC by following these rules. Some simulation of certain missing language features is required and some GOTOs inevitably creep in. But by keeping the notion of just three flavors of control blocks in mind, a surprisingly good job of structured programming can be done. If you still use BASIC, I encourage you to read a series of articles on structured programming in BASIC by Arthur Luehrmann in the May, June and July 1984 issues of Creative Computing. Unfortunately, Creative Computing is no longer published, but perhaps you or a friend has these back issues in the dusty magazine archives.
More iteration
I imagine you're pretty comfortable with the ideas behind action blocks and selection blocks, but let's take a close look at the iteration, or repetition, constructs. I'm sure you're familiar with the simplest type of loop, which looks like this in BASIC:
FOR I = 1 TO 10 calculate something NEXT I
In other languages, such a loop is commonly called a DO loop and is terminated by an END or END DO statement:
DO I = 1 TO 10 calculate something END
In either case, some test is used to determine the number of times the loop is executed. In these simple examples, a variable called I (the index variable) is incremented after each iteration and compared to the value 10. If I is less than or equal to 10, the statements in the loop are executed again; otherwise, execution of the loop terminates. Here we're assuming that the value of I will go up by one on each iteration. Of course, you can set a different step interval with a statement like: DO I = 1 TO 10 BY 0.5.
Here's the key question: Is the comparison done before the loop is executed or after? There's a big difference. Suppose I has a value of 20 at the time this loop is encountered in the course of executing the program. Will the loop be executed (since the value of the index variable is already greater than 10) or not?
In Atari BASIC, the comparison is done after the contents of the loop are executed, so the loop is always executed at least once. I think this is generally true of simple FOR/NEXT and DO/END loops. Many modern languages resolve any ambiguity by providing two explicit statement choices: DO WHILE and DO UNTIL. In a DO UNTIL loop, the termination condition is tested at the end of the loop, so the loop is always executed at least once. The simple FOR/NEXT loop in BASIC is thus a DO UNTIL type loop. In a DO WHILE construct, the termination condition is tested at the beginning of the loop. If the termination condition is already true, the contents of the loop aren't executed at all.
One important point is that DO WHILE and DO UNTIL loops need not rely on a changing index variable in the termination test. Any logical expression can be used, such as: DO UNTIL STATUS = ‘DONE’. It also may be possible to have complex combinations of termination conditions, either of which could cause loop execution to cease. Consider this example, which will terminate either when I is greater than 100 or when J becomes less than or equal to 30:
D0 I = 1 To 100 BY 10 WHILE J > 30 calculate something END
Maybe it will help to see a visual representation of these two looping structures. I'm sure you're familiar with flowcharts, in which action statements are represented with rectangles and decisions with diamonds. Figure la uses a fragment of a flowchart to illustrate that, in a DO WHILE loop, the conditional test is done before the action statements are executed. In Figure 1b, you see that the conditional test for a DO UNTIL is performed after the action statements are executed. I'm always getting these two confused, so maybe these simple diagrams will help.
FIGURE 1A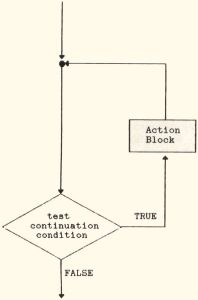
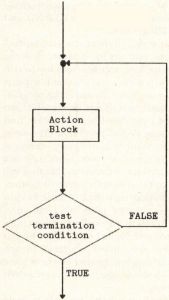

Once upon a time we talked about using another diagramming technique to depict the structure of a program module: action diagrams. You may recall that, in an action diagram, a loop is denoted by a double horizontal line, which encloses the action statements in the loop within brackets. You can distinguish between DO WHILE and DO UNTIL logic by placing the double horizontal line at the top or the bottom of the loop bracket, respectively. Figure 2 shows what you get.
There are times when you want execution of a loop to end prematurely, for a variety of reasons. Bad input data may have been encountered, some error condition may have cropped up or whatever. Remember that we want to write our code so that each control block has only one logical exit point, so let's resist the impulse to GOTO out of the loop. A DO WHILE is a good approach, because you can put the anticipated error or exit conditions into the WHILE clause:
DO I = 1 TO 10 WHILE EOF = ‘FALSE’ AND INPUT = ‘OK’
But things can get tricky if you don't have a DO WHILE available; you may just have to violate the one-exit rule. Some languages provide a command like LEAVE for premature loop exits. In BASIC, you can set the index variable to its termination condition, so that the loop isn't executed anymore; FORTRAN won't let you do this. A more graceful solution is to use an IF block that tests for the abnormal termination condition right inside your DO block:
DO I = 1 TO 10
IF EOF = ‘FALSE’ AND INPUT = ‘OK’ THEN
DO
calculate something
END
END IF
END
This is basically a way to simulate the DO WHILE command with your own explicit test. Note the innermost DO/END block without any loop criteria on the DO statement. This is really defining an action block to be executed within the selection block (IF/END IF), not a loop block. If you prefer, you can think of this as a loop block that gets executed exactly one time.
Let me out!
The one-entry, one-exit concept applies to individual modules just as it does to loops. Suppose you're calling a subroutine from a main program. You should always enter the subroutine at its top and exit at its bottom. This seems straightforward enough, but there are several ways things can go awry.
Some languages permit multiple entry points to a called procedure, but this is a bad practice. For example, in BASIC you may have seen the use of GOSUB in this form:
10 IF A = 1 THEN GOSUB 1000 20 IF A = 2 THEN GOSUB 2000 30 END 1000 calculate something 2000 calculate something else 2010 RETURN
Essentially what we have here is one subroutine (Lines 1000-2010) with two entry points (Line 1000 or Line 2000). If A = 1, then control is passed to Statement 1000, it drops through to Statement 2000, then returns at Statement 2010. But if A = 2, only the Lines 2000 and 2010 are executed. Concise, but very confusing; don't do it. If it's necessary to selectively execute certain statements in the subroutine under only certain conditions, put a test for those conditions at the top of the subroutine, or (even better) write two separate subroutines.
Similarly, each subroutine should have only one exit point or RETURN statement. But now something of a dilemma crops up. Suppose that we're being good little software engineers and are programming very defensively, writing lots of code at the top of the subroutine to validate ("audit") the input data. If errors in the data are encountered, we want to abort the operations in the subroutine and return to the calling program with some indication of what went wrong. How can we handle this if we only want to have one exit point in the subroutine? I can think of three alternatives.
- Forget about the one-exit rule and have multiple RETURN statements in the subroutine, one for each failed audit plus the proper one at the very end.
- Forget about the no GOTO rule and have a GOTO after each failed audit, which transfers control to the single RETURN statement at the end of the subroutine.
- Nest our audit tests (which are probably IF statements) as deep as necessary so that only conditions which pass all the tests finally work their way to the inner sanctum where the actual subroutine code resides.
It seems that we have a real quandary here. All of these approaches seem to violate one of the structured programming rules we're trying to abide by. Actually, the third scenario is okay if we have only a couple of audit conditions, because nesting IF statements two or three levels deep is perfectly fine. More levels of nesting than that becomes a problem both in terms of readability (do you want to match up six or seven END IF statements with the corresponding IFs on previous screens?) and because, if you're indenting nicely at each IF level, you may wind up with awfully short lines available for the actual subroutine code in the middle of the IFs. Not good.
My preference in handling the validation question is to think of the blocks of audit code as a "filter" through which the data must pass in order to wend its way to the heart of the module. I tend to put each audit block at the same level of indentation and have a RETURN statement in each block. The main processing section of the procedure has only a single RETURN statement.
Using the filter analogy, any time a piece of bad data is encountered, the RETURN statement acts as a block that prevents the process from continuing. I find that this approach keeps the code easy to read and modify, although I am violating the one exit rule. The next best solution would be to GOTO the single RETURN statement each time an audit fails, but I find this approach to be a little harder to read.
It might be useful to let the calling program know why processing was halted in a subroutine. The calling program will take different actions depending on the cause of the error, be it bad input data, mathematical impossibilities in the computations, file I/O problems or whatever. One way to do this is to pass a return code back to the calling program. The numeric value of the return code might represent the sequence number for an error message to display to the user. The interpretation of the error numbers could rely on a table or external file of messages or actions to match the return codes.
Alternatively, the return code might actually be the name of a procedure to call for handling the error or otherwise transferring execution control. By convention, a return code of 0 usually indicates that no error was encountered.
Wrapping up
The structured programming concepts we've talked about here are all geared toward making the programs you write more understandable to human beings. The computer doesn't care if your program makes sense, so long as it compiles properly. But anyone who must understand how your program works needs all the help he or she can get. You can provide that help not only by using good structured programming practices, but also by using common sense. Keeping your code clear and simple, rather than cute, condensed or clever, will go a long way toward writing programs that are easy to read, comprehend and alter.

After receiving a Ph.D. in organic chemistry, Karl Wiegers decided it was more fun to practice programming without a license. He is now a software engineer in the Eastman Kodak Photography Research Laboratories. He lives in Rochester, New York, with his wife, Chris, and the two cats required of all ST-LOG authors.