TUTORIAL
SOFTWARE ENGINEERING
Testing 1,2,3
BY KARL E. WIEGERS
After receiving a Ph.D. in organic chemistry, Karl Wiegers decided it was more fun to practice programming without a license. He is now a software engineer in the Eastman Kodak Photographic Research Laboratories. He lives in Rochester, New York, with his wife, Chris, and the two cats required of all ST-Log authors.
When last we met in this forum, I gave you carte blanche to furiously generate code, with the proviso that you base the programs you compose upon the detailed, structured-design approach we have contemplated in the past several months. I also asked you to think about what is meant by "software quality." After all, if we can't define quality, we will surely have trouble attaining it. And the goal of software engineering is to write high-quality programs as efficiently as we can.
If you've adopted the software-engineering strategy for your latest project, by now you should have a number of elementary program modules sitting around the house, waiting for something to do. The next step is to splice them all together, and then your project is complete (except for the oft-ignored but all-important documentation, which I strongly suggest you finish before moving on to the next project). Unfortunately, this assembly step is not as easy as it might appear. You'd like to have confidence that the program you write will indeed do what it is supposed to. Without testing, there's no way to know if this is the case. And even with the most thorough testing, there's no way to prove that the program is correct.
In this article I want to explore various stratagems for testing your software, both at the module or unit level and in its completed form. We'll also talk about various ways to combine your separate modules into an integrated system with the fewest possible errors.
One theme of our discussion is software quality assurance, a guiding principle that should always be part of your computer-programming thought process. Let's consider that a high-quality software system is one that's delivered to the users on time, costs no more than was projected and, most importantly, works properly. To work properly, the system must be as nearly error-free as possible.
There are three separate aspects of bug control to keep in mind. The software-engineering philosophy is directed toward bug prevention. The purpose of testing is bug detection. And, of course, the process of debugging pertains to bug correction. If the specification, design and implementation phases were perfect, we could skip the second and third steps entirely. But they aren't. As a consequence, testing takes up a very large portion of the software development effort.
Why test?
I begin with the assumption that all of my readers are human beings. The sad fact is that, as human beings, we make mistakes—lots of mistakes—even when we try very hard not to. Unfortunately, it's quite difficult to spot most software mistakes. The principal tangible aspects of computer software are source code and program outputs; so those are the places we must search most diligently for errors.
The software-engineering philosophy is intended to head off many potential errors at the pass, before they make it into finished products. However, many bugs inevitably slither in; some as simple source code typos, others buried within the intricacies of algorithms and logic. Goofs in source code often can be detected with the aid of computer tools, such as smart program editors or compilers that detect syntax errors due to misspellings and the like.
But many bugs only appear when the program produces some unexpected result upon execution. The responsible software developer must therefore run his products through a wringer, trying to unearth every lurking critter by well-designed tests and traps. If you don't find them, one of your customers eventually will. Why do you think so many commercial programs have a huge disclaimer printed in the manual that boils down to "We aren't responsible for the horrible things that might happen to you because this program is defective"?
In short, "testing" is the process of executing a computer program with the specific intention of finding errors in it. A successful test is one in which an error is revealed, not one that the program passes with flying colors. Always keep in mind that the goal of testing is to break the program. If a well-designed test case causes an execution error or produces faulty output, the test didn't fail—the program did. You can never demonstrate an absence of errors (with very few exceptions); so we'll do the next best thing and try to find some. At least then we have something to work on.
Testing versus debugging
Testing a program is not the same as debugging it, although testing is an important precursor to debugging. A test is intended to reveal the existence of errors. The debugging step, of course, is intended to identify and rectify those errors. In this sense, a test is an objective activity that could even be performed by the computer itself. An automated execution of a wide variety of carefully planned test cases is a common testing procedure. However, it's up to a human being to identify when a test fails, by comparing actual results with expected results. And then it's up to a human being to try to figure out where in the blazes the problem is coming from and how to make it go away.
The debugging process is just another aspect of programming, in that source code gets modified, recompiled and relinked prior to rerunning the test to see if you've been successful. As such, debugging is subject to all of the pitfalls that can occur during the original programming phase.
Actually, things are worse than that. During initial programming, you probably have an overall picture of the module structure in your mind (and on paper), and therefore you can spot some of the little inconsistencies that arise. But during debugging, you're concentrating on a specific function or section of code and it's easy to forget the relationship between that part of the program and the rest. Hence the introduction of new errors during the debugging process is likely.
Wiegers's Eighth Law of Computing states, "The fixing of one bug introduces at least two new latent bugs." Please attempt to violate this law whenever possible. The worst part is that the new bugs are usually hidden (latent), and only reveal themselves at some later date when they confuse you even more. This is one reason why your module documentation should include a running history of all modifications made to the module; so it's a little easier to determine when a change might have introduced other problems.
Before testing: inspections and walk-throughs
A moment ago I said that we can look for errors in both source listings and program output. (You can also look in object listings or memory dumps, but that's not much fun unless you think best in binary.) Let's start with the source listing. It's very important to visually inspect the source code before attempting to execute it. This is sometimes called a "desk check," and it's something you shouldn't gloss over. The desk check might catch the obvious typographical errors, missing quotation marks or parentheses, missing END statements and so on. Make sure each statement makes sense. If you can't see why it's there, maybe it doesn't belong there Make sure your statements conform to any programming standards established by you, your organization or the language being used.
The bad news is that it's very difficult to inspect your own program effectively. This is like trying to proofread your own writing. You know what the thing is supposed to say; so your brain tends to "see" what you expect, no matter what's really there. For example, there are a few (fortunately just a few) words that I consistently misspell, and I never seem to spot them during manual proofreading.
A possible solution is to solicit the aid of a friend or two. On most commercially oriented software projects, there are several developers involved so they can inspect each other's work. I don't know how many times I've stared at a source listing, knowing that something trivial was wrong, but was simply unable to find it until someone peeked over my shoulder and spotted it immediately. Hint: Make sure your friend is skilled in the language and computer environment in which you're working.
A more formal way to do this is to carry out a "structured walk-through" of the code. Many software groups conduct walkthroughs at various checkpoints throughout the project's life, including design as well as code walk-throughs. You have to be a little careful in a walk-through, and the rules should be agreed upon in advance. Since the goal is to uncover problems with the design or code before the project advances any further, human egos become involved. No one likes to see his work torn to shreds in a public forum. On the other hand, if all the walk-through participants just nod their heads and say, "Uh, huh" as the developer directs the walk-through, you probably won't accomplish much.
I've found structured walk-throughs to be very helpful in many instances. Remember that the later in the project development that an error is found, the more difficult and expensive it is to correct. Hence I'm always glad to have someone point out a problem area early on. Also, different programmers have different styles, and sometimes another person can point out a more efficient or clearer way to accomplish a specific task. One more advantage in sharing your work in a public group is that your associates become aware of what you're doing and how you're doing it. You might have a module one of them could use, or vice versa, and reusing existing code is the easiest way to write a new program.
Design walkk-throughs are especially helpful if you've been drawing data-flow diagrams by hand. It's very easy to leave a data store or an external off a child diagram when it appears on the parent for example. Another few pairs of eyes trying to make sense of your diagrams might catch the flaws you overlooked. An even better way to make sure your DFDs are consistent is to let the computer keep an eye on you. Various computer-aided software engineering (CASE) programs exist for just this purpose: CASE will be the topic of a future installment in this series.
Testing sequence
Let's turn our attention to actually testing completed modules. There are two distinctly different phases to this. First, of course, is to make sure that each module does exactly what it is intended to and does it properly. (Remember that we can't really prove correctness, but we'll do the best we can.) And second, you must try to convince yourself that the module does its job correctly in the context of the entire program. It's quite possible to have a module that works perfectly on its own, but fails when it is integrated with the other modules in the system due to errors in the data connections between modules.
Following individual module testing, then, comes "integration testing," which should reveal any problems arising because of interface errors among the components of the system. "System testing" is intended to search for errors by testing the completed system, either in a simulated production environment or in the actual environment in which it will ultimately be used.
The ultimate test, of course, is to have the end users (or suitable representatives) run the program and try to find situations in which it fails to meet their requirements. This is called "acceptance testing." You've probably heard the term "beta testing,"which refers to the evaluation by customers of a new piece of software prior to its official release on an unsuspecting public. I firmly believe that end users should be heavily involved with a software project from its very inception; after all, whom else are you trying to please? (This statement obviously does not pertain to those of us who program strictly as a hobby.)
Beta testing helps you get as close as possible to delivering an acceptable product, because end users will always approach testing differently from developers. The user's testing emphasis will be on trying to make the program fail in a real-world environment, without knowing anything about the program's internal structure. When you're intimately familiar with a system, it's difficult to take a step back and put yourself in the user's shoes. It also pays to remember Wiegers's Ninth Law of Computing: "After you have trapped for all conceivable errors, the users become more creative."
How can you tell if a test ran properly or revealed an error? Only by comparing the module's or system's performance with that expected. And how do you know what behavior is expected? From the specifications for the module or system. Now you know another reason why we software engineers spend so much time writing specifications: It helps us to know when we've properly completed our work. One question I always ask myself when beginning a software project is "How will I know when I'm done?" Without specs, no test makes any sense.
Naturally, no one really wants a program to fail. However, since we can't prove that it will always work correctly, we must try to make it fail during testing by feeding the system a wide variety of carefully thought-out inputs and seeing what it does. Now let's see some approaches to try for this activity.
Bug in the box
One approach to module testing is to treat the module as a black box, in which you neither know nor care what goes on inside it. You feed the module a specific set of inputs and compare the outputs to those demanded by the specifications. If they match, the test did not reveal an error. This approach is called "black box" or functional testing.
At the other extreme, you design test cases based on an examination of the program logic in the module. You attempt to execute every instruction at least once, and try to exercise every branching instruction (like IF or CASE) at least once in every possible direction. (Normally this is impossible, because there are just too many possible execution paths through the module.) This approach is called "white box" or structural testing.
Each method has its advantages, but you'll generally want to use some mixture in your testing strategy. Testing by users is black-box testing. They don't care how the program works, they just want it to do the right thing. Conversely, it's impossible for users to do white-box testing, because this requires the ability to study the source code when designing test cases. Why should the user care about source code?
Exhaustive structural testing really isn't feasible from a time and cost point of view. Just about every module will contain some logical branching instructions, and the more of these there are, the more possible sequences of statement execution there are for the whole module. The number of such execution pathways quickly gets out of hand. On the other hand, you definitely want to try to execute each statement in the module at least once. Any unexecuted code could contain bugs that would only be manifested in the hands of the user, who undoubtedly will make you aware of his discovery posthaste.
Similarly, exhaustive functional testing would mean that every possible combination of input data is supplied to the module, which then attempts to deal with it as best it can. Errors are revealed by the inability of the module to cope with specific inputs (like getting a letter when it expects a number), and by incorrect output being produced from legitimate input. Except for the most trivial possible data inputs, such as a single one-character variable, it's clearly impossible to test all possible input combinations.
We're reluctantly forced to conclude that it is impossible to completely test any piece of software. The module can be wrong, the specifications can be wrong, the test cases can be wrong, the interpretation can be wrong and a nearly infinite number of tests might be required to cover all the possibilities. Whatever shall we do? We shall devote careful attention to test-case design, that's what.
Test-case design
The time to begin designing your test cases is during system design, not after implementation is complete. At least you can devise your functional test cases then, because you have the system specifications in hand (right?). The functional tests for each module can be designed when you've completed the partitioning process and reached the stage of writing process narratives. Devising structural tests may have to wait until you've completed coding each module, because only then will the detailed structure of the module be known.
If you're writing programs for use by people other than yourself, you probably are used to "defensive programming." This refers to the practice of taking precautions against invalid input data being accepted and processing attempted. You should examine your module for any assumptions the logic makes concerning the existence, type and allowable ranges of inputs. Then add code at the beginning of the module to filter out unacceptable inputs. Use some judgement, because you may reach the point of diminishing returns if you carry this "auditing" of input data to an extreme. Nonetheless, defensive programming is a vital part of any software intended for public consumption.
Your module-testing approach then requires two kinds of test cases. One type supplies inputs designed to exercise your audit code and make sure that faulty input data is rejected. The second class of test case involves only valid input data, and is intended to look for problems in the part of the module that actually does the work. A common problem with released software is that some defensive code in the module that was never tested contains a bug, which results in an execution error when some unfortunate user just happens to trigger that audit by supplying bad input data.
Good test-case design is hard! I'll assume you can write test cases to assess the effectiveness of your input data audits. Keep the following additional points in mind as you think about how to test the working parts of your modules. Note that these recommendations involve a blend of structural and functional testing.
- Consider the allowable ranges of all input variables. Test the extreme values of allowable entries: smallest and largest numbers; fewest and greatest number of characters in an input string; first and last elements in an array; fewest and greatest number of parameters that could be supplied; smallest and largest allowable array dimensions and so on.
- Construct representative cases across the spectrum of possible inputs. For example, if your database program can handle four kinds of activities (view, change, delete, add) have cases of typical data for each of these. If your chemistry calculation program can handle 15 different chemical compounds, you should have a test case for each one of them.
- Examine the code and design test cases to make sure that every executable statement is encountered at least once.
- Examine the code and devise tests to ensure that every conditional branching statement is executed at least once in each direction. For CASE/SELECT constructs, test every possible CASE. However, don't try to cover every combination of branches that could possibly be encountered, unless you're serving about 1,000 consecutive life sentences for the heinous crime of software piracy.
- For each loop, devise test cases that will produce zero iterations of the loop (i.e., it isn't executed at all), one iteration and the maximum number of iterations. Make sure that DO...WHILEs and DQ.UNTILs do what you want.
- There may be specific input situations that you want to try out, based on anticipated execution modes. Devise special test cases for these conditions to supplement the general exercises from the previous steps.
- Build a library of test cases that can be rerun whenever a change is made in the program during the maintenance phase. These test data sets and the output they produce should become part of your system documentation so that another software engineer can properly test your system, if he has to make changes in it in the future.
- Above all, look at the output from the test. It's all too easy to run a test; see that the program did not crash and conclude that no problems were revealed. You don't know this for a fact until you compare the actual output with that anticipated, either based on the specifications for the module or by comparison with results from a previous error-free execution of that same test case.
Now that you've designed all these great test cases, what do you do with them? It's not always easy to test a lone module out of context, so we need an effective mechanism for testing the individual modules. We also need some good ways to join the modules together into the final system and look for errors in the data interfaces between modules. Fortunately, some other software engineers have already thought about this for us.
Module integration and integration testing
Big-Bang. The simplest way to integrate your modules into the final system is just to plug them all together and declare the project complete. This is referred to technically as "big-bang" integration and colloquially as a "catastrophe." Unless you have a very simple system or tend to win a lot of lotteries, be prepared to leave town if you try this approach and dump the result in someone else's lap.
Actually, big-bang integration might work sometimes, but I wouldn't put much money on it. Even if all your modules are perfect, any flaws in the data interfaces between them will cause system problems. This approach turns integration testing into purely system testing. My advice is to not try big-bang unless you're working on a very small program.
Top-Down: Top-down and bottom-up integration and testing are good techniques for evaluating individual modules in the context of others. In top-down testing, you begin with the main program, and then successively merge and test modules at lower levels in the calling hierarchy. Remember that the structure chart is a tool for depicting the hierarchical relationship of modules.
Top-down testing presents a couple of surmountable problems. Consider a simple structure chart like that in Figure 1. The main program calls module A, which calls module B and passes some of the results from module B back into the main, which then forwards those results into module C. In the top-down approach, we first join the main with modules A and C. But how can we test module C if it depends on the output from module B, which hasn't been integrated into our system yet?
One answer is to use "stub modules" to simulate the behavior of lower-level modules like module B before the real ones are glued into place. The official module B would be replaced by a stub module B, which has the same data interface as the real one and passes back a fake set of outputs that simulate what the real module B would do (if it functioned properly). These fake outputs eventually get supplied to module C for testing the connection between it and the main program.
This is all very convenient, but the use of stubs like this poses another question. What kind of fake data should the stub return, in order to not compromise the validity of the tests applied to module C? The answer depends on the specific situation. You might want to use the fake data returned from the stub just as a way to evaluate the module-A-to-main connection, and never actually give the fake stuff to module C. You can see that using stubs as substitutes for the real lower-level modules requires some thought. It can be more complicated to write effective stub modules than you might think. But if you don't write stubs that allow you to run all of your test cases for module A, your testing process will be incomplete.
Another potential problem arises because of the fact that input/output operations ations in your system might be carried out in very low-level modules. Since those may not appear until the latter stages of top-down integration, how can you even get the test data into the main and module A in order to look for bugs in module A? A thorny issue. One approach is to begin the top-down integration so as to incorporate the modules that perform physical I/O as quickly as possible. Another is to try bottom-up integration, either as an alternative to or in conjunction with top-down.
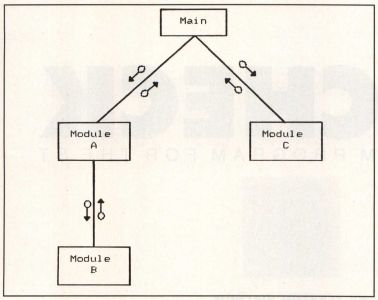
Bottom-Up: In contrast to top-down testing, the bottom-up approach begins with the lowest-level modules in your structure charts and links them to their superordinates (the higher-level modules that call them). Once linked, the subordinate member of the pair is tested. Based on Figure 1, we would start a bottom-up integration with module B, which we then connect to module A. After satisfactorily testing module B, module A is linked to the main and then tested. The main only gets tested after the entire system is integrated in this fashion.
The way I've described this scenario, any problems with the real module A could interfere with the testing of module B. Hence we can't use the actual module A at the outset. Instead, we write a little "module driver" as a stand-in for module A during testing. The module driver is analogous to the stub module used during top-down integration. The purpose of the driver is to feed appropriate test-case data into module B and see if anything goes wrong. This is a pretty good way to see how module B responds to a given set of inputs from A, and you can use most of your test-case strategy exactly as it was originally devised.
Once you've decided that you can't find anything wrong with module B, you can replace the driver with the official module A, hook the pair up to a driver for the main and see if module A has its act together. Thus goeth bottom-up integration and testing.
In practice, I usually employ a combination of top-down and bottom-up integration. I try to stay away from the big-bang approach. Sometimes this is referred to as "sandwich testing." I may begin with the main program, since I can see from the structure chart all the other modules that it calls. I'll use stubs to make sure the main goes where it's supposed to when it's supposed to. Then I turn to the lowest-level modules, since their functions are well-defined from the process narratives. I'll test these with little drivers, then start building the system from a foundation of well-behaved (so far as I can tell) modules. Eventually, the whole thing hangs together, and sometimes the system even does exactly what I want.
Special topics
In the past six months or so, I've presented some of the basic ideas of modern software engineering. This discipline is still in its infancy, but there are many indications that it offers substantial advantages over previous methods for building software systems, particularly large ones. (In the real world, a "large" system may be on the order of several hundred thousand lines of code. What comes beyond "large"? "Incomprehensible"?)
Our brief survey of software engineering so far has focused on the traditional stages of system specification and analysis, structured system design, detail design, testing and integration. There are many other important facets of software engineering that we'll be exploring in future articles. These include software quality assurance, alternative software life cycles, the exciting area of computer-aided software engineering or CASE, system and program documentation, the maintenance issue, software metrics (measurements), software project management and data-oriented design. A foray into structured programming concepts might not be a bad review topic either. Stick with me as we continue to explore ways to address the software crisis as we move into the 1990s.
Bibliography
These are two thorough and very readable books on software testing and system integration. As a general hint, if you're browsing through software engineering books, go for those with the most recent publication dates since the field is evolving so rapidly.
- Boris Beizer. Software System Testing and Quality Assurance. Van Nostrand Reinhold, 1984.
- Glenford J. Myers. Software Reliability: Principles and Practices. John Wiley & Sons, 1976.