Replacing The INPUT# Command
Jerry E. Dunmire
San Jose, CA
At last you have your PET and now you can keep track of all those magazine articles, recipes, addresses or whatever else you promised your spouse! At least that's how I felt, and I immediately sat down to write the programs.
If you have tried to write a program that uses the INPUT command, then you know the problems I encountered. The INPUT command will not accept commas, quotes, or colons and using the GET command to construct a string is very slow. Since a proper bibliography of magazine articles must contain quote marks, I was stuck with the GET command. There had to be a better way.
There is! Nothing says that all programs must be written in BASIC. I could write a machine language routine to replace the INPUT# command. The new routine would accept all characters. Replacing the INPUT# command would also solve the same problems I encountered when reading from the tape or disk.
There are three items that we need to know in order to write a new version of the INPUT# command: how strings are stored, where the string is located, and how to input characters. The PET/CBM Personal Computer Guide by Adam Osborne and Carroll S. Donahue provided the information on string storage. Raymond Diedrichs explained how to input from a file in his article "Pet File I/O in Machine Language" COMPUTE! #11.
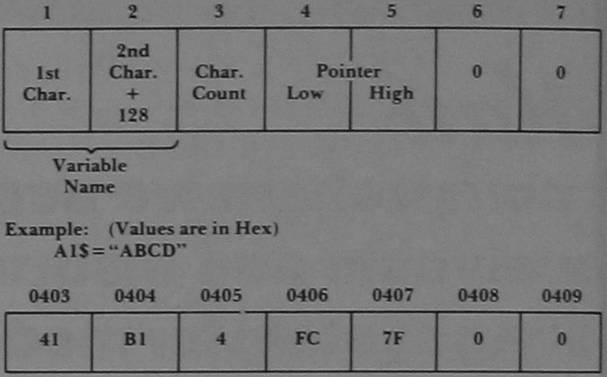
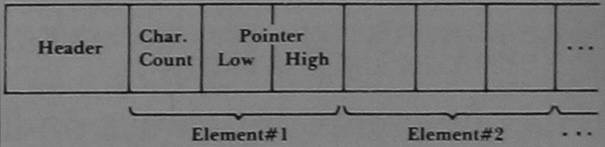
Strings are stored at the top of the available memory. As each string is entered, it is added to the bottom of the list. In order to identify a particular string we must know where it begins and how long it is. The PET uses one byte to represent the length of the string, and two bytes to identify the address where the string begins. The particular format that identifies a string depends on whether the string is an element of an array or a simple variable.
A simple variable has the form shown in Figure 1. If the string is an element of an array, it would be identified as shown in Figure 2. We can disregard the information in the header of an array.
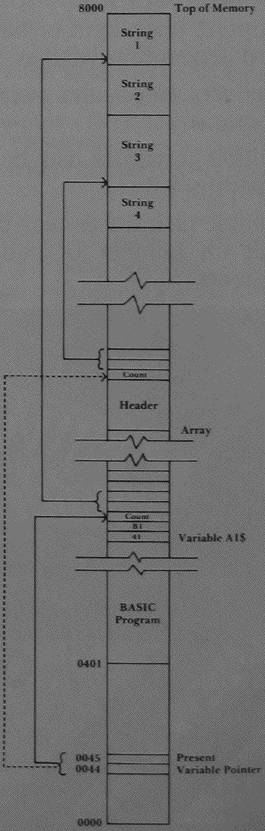
This is only part of the information we need to locate a string in memory. The location of the pointer to the string is still unknown. Must our routine search for the name of the particular string we wish to input? Well, it could, but there is an easier way. Locations $44 and $45 point to the last variable referenced. If that last variable were the string we wish to input, then these locations will point to the length of the string, and the next two locations will be the address where the string is stored. Figure 3 shows the relationship between locations $44, $45, variables, and strings.
Reading characters from a file is even easier than dealing with strings. If a file has been opened by a BASIC statement, the subroutine at $FFC6 will set the file up so we can read from it. Then the subroutine at $FFCF will input a character from that file. When we have all the characters we want, the default I/O devices should be restored.
Armed with this knowledge, I wrote two routines. The two routines are named READString and INPUTLine. They are located in the second cassette buffer. Both use locations $44 and $45 to locate the variable, so the last variable you reference before calling these routines must be a string.
READS inputs a fixed number of characters from file #1. The number of characters is determined by the length of the string referenced by locations $44, 45. As the characters are read in, they replace the characters that are already in the string. This routine will cause strange problems if locations $44, $45 point to a string with zero length. To prevent this occurrence, I use the following commands to call READS:
10 IF LEN(A$) THEN SYS(826)
If A$ has a zero length, READS will never be called. As you can see, the starting address of READS is 826 ($033A).
The version of READS shown in Program 1 reads one additional character after it has filled the referenced string. The file has a carriage return at the end of each string. To remove this extra character input, place NOP's ($EA) in locations $0361 through $0363.
INPUTL also uses file #1. A carriage return must mark the end of a string just like the INPUT# command. INPUTL will accept any character other than a carriage return. Up to 80 characters can be input. If more than 80 characters are input, the ST variable will be set to a value of—1.
INPUTL works more like INPUT# than READS does. As the individual characters of a string are input, they are placed in an input buffer. Only after the string has been terminated with a carriage return is it transferred to the string storage area and assigned to the variable pointed to by $44, $45. The string is copied from the input buffer to just below the string storage area. Then the pointer to the beginning of the string storage area is adjusted to account for the new string.
I use the following line to call INPUTL, but you can use any function that leaves locations $44, $45 pointing to the variable you wish to input.
10 A$ = "" : SYS (872)
As you can see, the starting address for INPUTL is 872. As with READS, if the last variable you referenced were not a string then the results are almost unpredictable and certainly bad.
You can change the file number used by these programs to suit your needs. Simply POKE the number of a file you have opened into location 827 for READLINE and 873 for INPUTSTRING.
INPUTL and READS will work with BASIC 3.0 or BASIC 4.0. If you need to use them with BASIC 1.0 then you will have to adjust all of the references to memory locations less than $0400 (1024 decimal).
INPUT# is still the fastest way to input a string. However, both INPUTL and READS are at least three to four times faster than using GET# commands. If you are short on memory, using the GET# command will be exceedingly slow since it will cause the garbage collection routine to execute more often than any of the other methods.
Program 1.
800 FOR ADRES = 826TO949 : READ DATTA : POKEADRES, DATTA 805 NEXT 826 DATA 162, 1, 32, 198, 255, 160 832 DATA 0, 177, 68, 133, 96, 200 838 DATA 177, 68, 133, 94, 200, 177 844 DATA 68, 133, 95, 169, 0, 133 850 DATA 97, 32, 207, 255, 164, 97 856 DATA 145, 94, 200, 132, 97, 198 862 DATA 96, 208, 242, 32, 207, 255 868 DATA 32, 204, 255, 96, 162, 1 874 DATA 32, 198, 255, 169, 0, 133 880 DATA 5, 32, 207, 255, 201, 13 886 DATA 240, 15, 166, 5, 232, 224 892 DATA 81, 240, 47, 157, 0, 2 898 DATA 134, 5, 76, 113, 3, 166 904 DATA 5, 160, 0, 198, 48, 165 910 DATA 48, 201, 255, 208, 2, 198 916 DATA 49, 189, 0, 2, 145, 48 922 DATA 202, 208, 238, 165, 5, 145 928 DATA 68, 165, 48, 200, 145, 68 934 DATA 165, 49, 200, 145, 68, 76 940 DATA 178, 3, 169, 255, 133, 150 946 DATA 32, 204, 255, 96