Disk File Recovery Program
David L. Cone, Sunnyvale, CA
Have you ever been working happily along on a program, updating it periodically on your disk, only suddenly to discover that something wierd has happened and you've apparently lost half of the programs on the disk. (I've even had the case where the programs disappeared from the directory while the number of blocks remaining stayed the same). Maybe what happened was that AFTER you scratched the program from the disk you found that the PET had also gobbled up your program in memory — (or you did). Or perhaps you had done a short 'new' of a disk only then to realize that valued programs were on it!
If you've ever been in this frustrating position of knowing your program was just sitting there on the disk with no easy way to get it back, this DISK FILE RECOVERY program will help — it will recover such programs. As long as you can still initiate the disk and have not written a new program over the file you want, you can recover it. It cannot recover programs from a disk which will not initiate or upon which a long ‘new’ (ie. a ‘new’ with a disk number) has been performed.
The disk works this way: When a file is placed on a disk, part of the information placed in the directory on track 18 is a pair of pointers giving the track and sector numbers of the block where the file begins. The first two bytes of this block are also pointers giving the next track and sector numbers. This process continues until the last block is reached. For the last block, a 00 is placed in the first byte and nothing appears to be done to the second. Files are stored in a somewhat alternating way below and above track 18. The first file is stored starting at 17,0 (track 17, sector 0). When track 17 is filled, the next new file appears to be started at 19,0 and so on back and forth. If you have lost or destroyed track 18, the problem is then how to find and identify the initial blocks of the lost files and then to recover the files.
This is what the RECOVERY program does! First, it gives you the choice of working with either the lower band (tracks 17 to 1) or upper band (tracks 19 to 35), and on which track you wish to stop. It sets up an integer array [D%(35,20,3)] which can receive for each block the "in" pointers (ie. the track and sector numbers of the block which ‘points’ at it) and the "out" pointers (ie. the track and sector number of the block at which it points. The program then scans the first track for these pointers. What we are looking for are blocks which have no "in" pointers, for they must be the ones pointed at by the directory and thus the initial blocks for any files. Next the program takes each initial block and follows that file through all its blocks to the end, filling in the array as it goes. Each subsequent track is similarly scanned and as new files are found they are traced. You have the option of stopping this process at any point. Meantime, the program has kept track of the start and end of each file and the number of blocks it uses. This summary is presented on the screen.
The next major problem is the identifying which file is which (since only the disk knows where a file was saved and on which half of the disk). The program offers you a number of appropriate options at this point, and the most useful one for file identification is labeled LOOK. LOOK pulls the initial block of any file out and extracts information that will probably allow you to identify the file. First, it displays in a useful form the first four pairs of bytes. The first pair are the pointers to the next block. If the file is a program the next pair of bytes tell where the program is to be loaded in memory. For Basic programs, this is usually 1024. The third and fourth pairs of bytes are from the program itself. They are the link and line number of the first instruction in the basic program. If the file is a machine language program or a sequential file, then you get weird and meaningless values for the link and line numbers. Next, LOOK gives you the first 48 bytes of the program in hexadecimal form (as if they were being examined by the machine language monitor). Finally, LOOK gives you a printed "translation" of the first 240 bytes. Basic commands are tokenized and appear as reversed characters or symbols. The link and line pointers also can look quite strange. However, numbers, variables, anything between quotes, and REM statements all appear as usual. Thus, if you have some convenient identifications at the beginning of your program, you will be able to recognize them. To see how this "translation" takes place, see lines 1360-1390 and 5090-5095. Eighty characters are scanned at one time and you can go from one set of eighty to another. With this amount of information it is usually quite easy to determine what any file is and if you wish to recover it.
Aside from LOOK, you have the following options: 1) SUMMARY REVIEW — this gives you the start block of any file and the number of blocks in that file. You need to know the start block to either look at or recover a file. Also, the number of blocks in the file may aid in its identification. 2) RETRIEVE A FILE — here is the point of all of this; now you get the program or file back! The program asks for all the essential things: starting track and sector, the name you want for the recovered file and whether it is a program or a data file. It gives one final chance to abort unless everything is ok and then it is off and running. 3) SCAN OTHER BAND, 4) DIFFERENT DISK, and 5) EXIT PROGRAM are all obvious.
The program itself, while complex in details, is straightforward in construction. It is divided into the following sections:
400- 492 Program description and credits 500- 595 Description of all variables 600- 696 Start of Program — Initial choices 700- 865 Search for initiator blocks 1000-1055 Print summary table 1100-1165 Choices 1200-1415 Performs LOOK option 1500-1655 Retrieves the file 4000-4076 General subroutines 5000-5109 Disk operation subroutines
"REM**" statements are used to show major divisions of the program while "REM @" indicates descriptive statements within these major divisions. I have used REM statements fairly liberally and these should help in tracing through the details of the program. A pair of REM statements (line numbers 1410 and 4003) need a special comment: if you have a machine language screen dump capability, you should SYS to them here. I use a shifted "P" to activate the screen dump.
A couple of final comments: If you search tracks in which there are no programs, you may get a disk read error (22 READ ERROR 13,0). If this occurs, simply type GOTO 1000 and you will be able to go on without any problems. I hope this program is as useful to you as it has been to me. I made it because I really needed it. You may not need it often, but when you do, the situation is likely to be desperate!
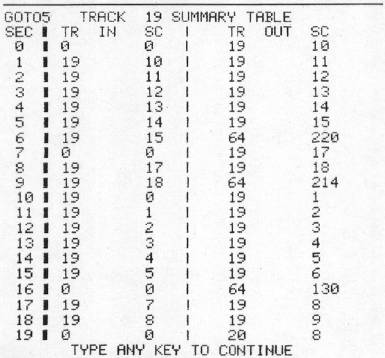
A summary table such as this is made for each track scanned. The zeros in the IN column indicate the initial block of a file. The 64 in the OUT column shows where a file ends.
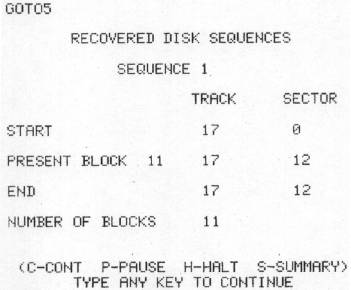
As each file is traced, this table keeps track of what is happening and summarizes the results.
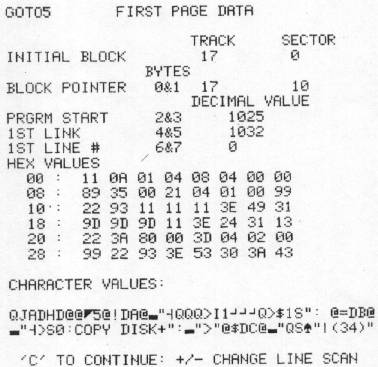
A typical BASIC program looks this way. Note the following: PRGRM START = 1025; typical 1st LINK and LINE # values; and identifiable features in the CHARACTER VALUES. (Unfortunately, my dump program does not give reversed characters which would assist in identifying BASIC tokens).

This program was put into high memory starting at 28672. Note the rather random CHARACTER VALUES, and FIRST LINK and LINE values.

The easiest way to identify this type of file is to observe the data items separated by "M" in the CHARACTER VALUES section. The "M" is the screen representation of CHR$(13) and is in reverse field on the screen.
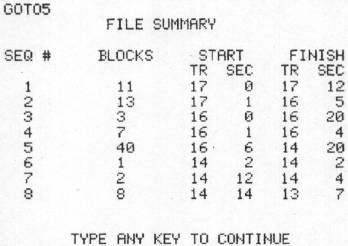
This table summarizes the completed scan results. The START track and sector numbers are needed to use the LOOK and RETRIEVE options.
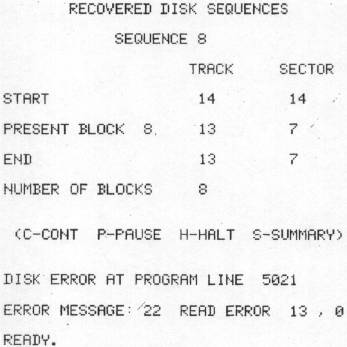
This is what you may see if you try to recover files from a part of the disk where no files have been written. Simply type GOTO 1000 to continue.